1. 프로젝트 개요
송도 국제도시의 아파트 실거래가 분석 및 가격 예측을 위한 데이터를 수집하고 정리하는 과정입니다. 본 프로젝트는 인천 연수구 송도 지역의 부동산 시장을 보다 깊이 있게 분석하고자 하며, 다양한 데이터 소스를 활용하여 입지 및 가격 변동 요인을 수집합니다.
2. 데이터 수집 개요
송도 국제도시의 아파트 실거래가 데이터를 수집하고 정리하는 과정을 정리하였습니다. 데이터 수집부터 데이터 전처리 부분까지 상세하게 다루었으며, 교통·편의시설·금융 데이터도 살펴봅니다.
3. 실거래 데이터 선정기준
1) 왜 아파트 데이터만 사용했는가?
본 프로젝트에서는 아파트 실거래가 데이터만 활용하였습니다. 그 이유는 다음과 같습니다.
1️⃣ 시장 대표성: 연수구에서 가장 많이 거래되는 주택 유형은 아파트로, 전체 거래의 90% 이상을 차지합니다.
2️⃣ 데이터의 일관성 유지: 단독주택, 다세대주택 등은 가격 형성이 복잡하고 비교가 어려운 경우가 많습니다.
3️⃣ 부동산 시장 분석 용이: 아파트는 동일한 단지 내에서도 가격 비교가 쉬우며, 입지와 가격 변동성을 분석하는데 적합합니다.
2) 연수구 주택 유형별 분포 그래프
아래 그래프는 인천광역시 연수구 내 주택 비율을 나타냅니다. 아파트 전체 주택 유형에서 91.6%로 가장 높은 비율을 차지하고 있음을 확인할 수 있습니다.

3) 왜 매매 데이터만 사용했는가?
송도동 매매와 전월세 데이터를 비교 분석한 결과 다음과 같은 결론을 도출, 그에 따라 본 프로젝트에서는 매매 실거래가 데이터만을 활용하였습니다. 각 거래의 신고제 시행 시기는 매매의 경우 2006년 1월 1일, 전월세의 경우 2021년 6월 1일입니다.
2015년부터 2024년까지의 데이터를 분석하는데 있어 매매 거래 신고 의무가 보장되어 신뢰성이 높고, 부동산 정책과 금융 환경 변화 분석등이 가능합니다. 전월세 계약의 경우 그 거래마다 조건이 다양하여 표준화된 비교가 어렵고, 시장 변동성 분석에 적절하지 않습니다. 따라서, 송도동의 시장 흐름과 정책 영향을 분석하기 위해 신뢰성이 높은 매매 데이터를 활용하고자 합니다.
1️⃣ 거래 건수 차이
| 항목 | 매매 데이터 | 전월세 데이터 |
|---|---|---|
| 거래 건수 | 24,645건 | 63,024건 (매매보다 2.5배 많음) |
| 선택 이유 | 거래량이 많지만, 분석 목적상 매매 데이터를 선택 | 전월세 거래가 많지만 계약 형태가 다양해 일관된 비교가 어려움 |
2️⃣ 데이터의 일관성 및 신뢰성
| 항목 | 매매 데이터 | 전월세 데이터 |
|---|---|---|
| 신뢰성 | 실거래가 신고 의무가 있어 데이터 정확성이 높음 | 계약 조건(보증금, 월세, 계약기간 등)이 다양하여 일관성 부족 |
| 가격 변동성 | 동일 면적·같은 아파트에서도 가격 변동이 명확하게 측정 가능 | 보증금과 월세 조합이 다르므로 직접적인 가격 비교 어려움 |
| 시장 흐름 분석 | 정부가 공식적으로 관리하는 데이터로 시장 흐름 분석에 적절 | 선입금(보증금)과 월세 변동성이 높아 패턴 분석이 어려움 |
3️⃣ 가격 변동성과 정책 영향
| 항목 | 매매 데이터 | 전월세 데이터 |
|---|---|---|
| 정책 영향 | 정부 정책(대출 규제, 금리, 세금 등) 영향을 직접 받으며 변동성이 높음 | 매매 시장의 후행적 영향을 받으며, 변동성이 크지 않음 |
| 시장 흐름 예측 | 장기적인 가격 흐름 예측 가능 | 월세 계약과 전세 계약 차이가 커서 시장 흐름 분석이 어려움 |
4. 아파트 매매 실거래량
1) 데이터 수집
공공데이터포털에서 제공하는 국토교통부의 아파트 매매 실거래가 자료를 활용하여, 2015년부터 2024년까지 인천광역시 연수구 송도동 일대의 거래내역을 분석하였습니다.
먼저, 2015년부터 2024년까지의 각 연도와 매월을 대상으로 반복문을 실행합니다. 각 월마다 DEAL_YMD라는 문자열(예: "201501", "201502" 등)을 만들어 API 요청 파라미터로 사용합니다. 그리고 해당 월의 데이터를 페이지 1부터 최대 5페이지까지 요청하는데, 각 페이지는 최대 1000개의 행(row)을 반환하도록 설정되어 있습니다. API 응답은 XML 형식으로 오며, xml.etree.ElementTree 라이브러리를 이용해 XML 데이터를 파싱합니다.
첫 페이지에서 데이터를 받으면, 첫 번째 항목의 자식 태그를 통해 컬럼명을 설정하고, 각 항목(item)의 자식 태그 값을 추출하여 리스트 형태의 행(row)을 구성한 후, 전체 데이터를 저장할 리스트(songdo_apt_data)에 추가합니다. 만약 특정 월에 데이터가 없거나 API 요청에 실패하면, 해당 월이나 페이지는 건너뛰게 됩니다.
또한, API 호출 간에는 time.sleep()을 사용해 요청 간격을 두어 서버에 과도한 부하가 걸리지 않도록 하고 있습니다. 모든 데이터를 수집한 후에는, pandas를 이용해 리스트를 데이터프레임으로 변환하고 CSV 파일로 저장합니다.
✔️ 출처: 국토교통부 실거래가 공개 시스템
수집 코드
import requests
import xml.etree.ElementTree as ET
import pandas as pd
import time
import certifi
# API 요청 URL 및 키 설정
call_back = "http://apis.data.go.kr/1613000/RTMSDataSvcAptTrade/getRTMSDataSvcAptTrade"
service_key = requests.utils.unquote("개인 Service Key")
lawd_cd = "28185" # 인천시 연수구 법정동 코드
songdo_apt_data = []
columns = []
for year in range(2015, 2025):
for month in range(1, 13):
deal_ymd = f"{year}{month:02d}"
print(f"{deal_ymd} 데이터 수집 시작...")
# 첫 페이지 요청
params = {
"serviceKey": service_key,
"LAWD_CD": lawd_cd,
"DEAL_YMD": deal_ymd,
"pageNo": 1,
"numOfRows": 1000
}
res = requests.get(call_back, params=params, verify=certifi.where())
if res.status_code != 200:
print(f"{deal_ymd} 데이터 요청 실패, 상태 코드 {res.status_code}")
continue
root = ET.fromstring(res.text)
items = root.findall(".//item")
if not items:
print(f"{deal_ymd} 데이터 없음")
continue
# 최초 데이터 수집 시 컬럼 설정
if not columns:
columns = [child.tag for child in items[0]]
# 첫 페이지 데이터 저장
for item in items:
row = [child.text if child.text is not None else None for child in item]
songdo_apt_data.append(row)
print(f"{deal_ymd} 페이지 1 수집 완료 ({len(items)}건)")
# 2페이지부터 최대 5페이지까지 데이터 요청
for page in range(2, 6):
params["pageNo"] = page
res = requests.get(call_back, params=params, verify=certifi.where())
if res.status_code != 200:
print(f"{deal_ymd} 페이지 {page} 요청 실패, 상태 코드 {res.status_code}")
break
root = ET.fromstring(res.text)
items = root.findall(".//item")
if not items:
print(f"{deal_ymd} 페이지 {page} 데이터 없음 (더 이상 데이터 없음)")
break
for item in items:
row = [child.text if child.text is not None else None for child in item]
songdo_apt_data.append(row)
print(f"{deal_ymd} 페이지 {page} 수집 완료 ({len(items)}건)")
time.sleep(1) # API 부하 방지를 위한 대기
# 데이터프레임 생성 후 CSV 파일로 저장
songdo_df = pd.DataFrame(songdo_apt_data, columns=columns)
songdo_df.to_csv("songdo_sale_apt_data.csv", index=False, encoding="utf-8-sig")
print("CSV 파일 저장 완료: songdo_apt_data.csv")2) 데이터 정제 과정
✔️ 필요없는 칼럼 제거 및 칼럼명 정리
✔️ 날짜 형식 변환 및 연월 데이터 생성
✔️ 평당가격 계산 추가
✔️ 전월세전환율 데이터 추가 ( 전월세 전환율 데이터 출처: 통계청)
✔️ 기본 통계를 통해 이상치 값 삭제하기
각 컬럼에서 공백(빈 문자열)의 개수를 세어 출력합니다. 이를 위해 is_emptystring 함수는 입력받은 Series의 값을 문자열로 변환한 후 좌우 공백을 제거하여 빈 문자열과 일치하는 값의 총 개수를 계산합니다. 이어서 DataFrame 내의 모든 공백 값을 정규 표현식을 사용해 np.nan(결측치)로 대체합니다.
다음으로, 인천광역시, 연수구, 송도동 정보를 데이터에 추가합니다. 이후, 데이터 타입을 변경하는 단계가 진행됩니다. dealYear, dealMonth, dealDay, floor' buildYear 컬럼은 정수형으로 변환하고, dealAmount 컬럼은 문자열에서 콤마(,)를 제거한 뒤 실수형으로 변환합니다. excluUseAr는 실수형으로 변환됩니다. 그리고 연, 월, 일을 합쳐 dealDate 컬럼을 datetime 타입으로 생성합니다. 추가로, dealAmount와 excluUseAr를 활용해 평당 가격(pricePerpy)을 계산하는데, 여기서는 1평이 3.3 제곱미터임을 반영하여 계산한 뒤 소수점 4자리로 반올림합니다.
마지막으로, 분석에 불필요한 컬럼들을 삭제한 후, 최종적으로 사용할 컬럼 순서를 재정렬하여 DataFrame을 정리합니다.이러한 과정을 통해 원본 아파트 거래 데이터에서 다양한 전처리 작업을 수행하여 분석 및 활용하기 적합한 최종 데이터셋을 구축하게 됩니다.
데이터 정제 코드
xls = pd.ExcelFile(r"yeonsugu_rent_conversion_rate.xlsx")
conversion_rate_df = pd.read_excel(xls, sheet_name="데이터")
# 데이터 변환 (연도-월을 행으로 정리)
conversion_rate_df = conversion_rate_df.melt(
id_vars=["주택유형별(1)", "지역별(1)", "지역별(2)"],
var_name="year_month",
value_name="rent_conversion_rate"
)
# 인천 연수구 필터링
conversion_rate_df = conversion_rate_df[
(conversion_rate_df["지역별(1)"] == "인천") & (conversion_rate_df["지역별(2)"] == "연수")
]
# 거래일에서 'YYYY.MM' 형태로 변환
songdo_apt_df["year_month"] = pd.to_datetime(songdo_apt_df["dealDate"]).dt.strftime("%Y.%m")
# 전월세 거래 데이터와 전월세전환율 병합 (left join)
songdo_apt_df = songdo_apt_df.merge(conversion_rate_df[["year_month", "rent_conversion_rate"]],
on="year_month", how="left")
각 칼럼별로 요약된 통계를 살펴보면 확인이 필요한 값들이 존재합니다.
저는 아직 미숙하여 직접 찾아보는 방식으로 데이터 전처리를 진행하였습니다.
songdo_apt_df = songdo_apt_df.loc[(songdo_apt_df['floor'] != -1) | ~((songdo_apt_df['aptNm'] == "송도웰카운티4단지") & (songdo_apt_df['floor']<6))]3) 데이터 사용 컬럼
| 컬럼명 | 설명 |
|---|---|
sdNm |
시/도 이름 (예: 인천광역시) |
sggNm |
시/군/구 이름 (예: 연수구) |
umdNm |
읍/면/동 이름 (예: 송도동) |
jibun |
지번 (토지의 고유 번호) |
aptNm |
아파트 이름 |
excluUseAr |
전용면적 (㎡ 단위) |
dealDate |
거래 날짜(YYYY-MM-dd 형식) |
dealAmount |
거래 금액 (만원 단위) |
floor |
거래가 이루어진 층수 |
buildYear |
건축년도 |
year_month |
거래 연월 (YYYY-MM 형식) |
pricePerpy |
평당 가격 (만원/평, 거래금액 ÷ (전용면적/3.3)) |
rent_conversion_rate |
전월세 전환율 (한국부동산원,지역별 전월세전환율) |
5.교통 데이터
1) 데이터 수집
이 코드는 인천 지역의 버스 및 지하철 역 위치, 승하차 수 등의 다양한 교통 데이터를 하나의 통합 데이터셋으로 병합하는 전체 파이프라인을 구현합니다.
먼저, 공공데이터포털에서 제공하는 CSV 파일들을 활용하여 지하철과 버스 관련 원본 데이터를 불러옵니다. 지하철 데이터의 경우, 불필요한 컬럼을 제거하고 컬럼명을 통일한 후, 국가철도공단에서 제공하는 역 주소 데이터와 일별 승하차 데이터를 병합하여 최적화된 지하철 데이터를 생성합니다.
버스 데이터는 버스 정류소 원본 파일과 정류장별 승객 현황 파일을 불러와 필요한 컬럼만 남긴 후, “노선/호선” 값을 ‘버스’로 지정하여 최적화합니다.
추가적으로, 데이터의 최신성을 유지하기 위해 카카오 API를 사용하여 실시간 버스 정류소와 지하철역의 위치 정보를 보완합니다. 버스 승객 데이터에 포함된 정류소명을 기준으로 API를 호출해 주소, 위도, 경도 등의 정보를 추출하고, 동일하게 카테고리 기반으로 송도 중심의 지하철역 정보를 조회하여 보완 데이터셋을 만듭니다. 이후, 원본 버스 정류소 데이터와 승객 데이터를 병합하고, API에서 보완한 정보도 추가하여 최종 버스 데이터를 완성합니다.
마지막으로, 이렇게 생성된 데이터를 모두 하나로 통합한 후 중복된 데이터를 제거합니다. 이 과정에서 인천 지역의 버스 및 지하철 역 위치, 승하차 수 등의 데이터를 하나의 통합 데이터셋으로 병합하며, 공공데이터포털의 CSV 파일과 API를 통한 실시간 데이터 비교 및 검증으로 데이터의 최신성과 정확성을 유지합니다.
✔️ 출처: 인천교통공사, 국가철도공단, 공공데이터포털
- 지하철 역사 정보: 인천교통공사_도시철도역사정보
- 지하철 역 주소 데이터: 국가철도공단_인천_지하철_주소데이터
- 버스 정류소 정보: 인천광역시_시내버스 정류소 현황
- 버스 정류장별 승객 이용 데이터: 인천광역시_정류장별 이용승객 현황
- 지하철 1호선 승하차 데이터: 인천교통공사_1호선 일별 승하차현황
- 지하철 2호선 승하차 데이터: 인천교통공사_2호선 일별 승하차 현황
데이터 수집 코드
import pandas as pd
import os
import time
import random
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 설정 및 전역 변수
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
]
SUCCESS_FILE = "bus_passenger_data_partial.csv"
FAILED_FILE = "failed_requests.csv"
ROUTES_CSV = "bus_routes.csv"
# 기존 제공 CSV 데이터 최적화
subway_raw_path = "인천교통공사_도시철도역사정보_2023-07-31.csv"
railway_address_path = "국가철도공단_인천_지하철_주소데이터_2020-11-23.csv"
subway_usage_1_path = "인천교통공사_1호선 일별 승하차현황_20240630.csv"
subway_usage_2_path = "인천교통공사_2호선 일별 승하차 현황_20240630.csv"
bus_raw_path = "인천광역시_시내버스 정류소 현황_2024-07-09.csv"
bus_passenger_raw_path = "인천광역시_정류장별 이용승객 현황_20250131.csv"
subway_optimized_path = "optimized_subway_data.csv"
bus_optimized_path = "optimized_bus_data.csv"
bus_passenger_optimized_path = "optimized_bus_passenger_data.csv"
# 지하철 데이터 정리
subway_data = pd.read_csv(subway_raw_path, encoding="cp949")
railway_address = pd.read_csv(railway_address_path, encoding="cp949")
subway_data = subway_data.drop(columns=["역번호", "노선번호", "영문역사명", "한자역사명", "환승노선번호", "환승노선명", "운영기관명", "역사전화번호", "데이터기준일자"], errors='ignore')
subway_data.rename(columns={"역사명": "정류소명", "노선명": "노선/호선", "역위도": "위도", "역경도": "경도"}, inplace=True)
# 지하철 승하차 데이터 정리
subway_usage_1 = pd.read_csv(subway_usage_1_path, encoding="cp949")
subway_usage_2 = pd.read_csv(subway_usage_2_path, encoding="cp949")
subway_usage_data = pd.concat([subway_usage_1, subway_usage_2], ignore_index=True).drop_duplicates()
subway_usage_data.rename(columns={"역명": "정류소명"}, inplace=True)
# 지하철 데이터 병합 (역 주소 추가)
subway_final = subway_data.merge(railway_address, left_on="정류소명", right_on="역명", how="left").drop(columns=["역명"])
subway_final = subway_final.merge(subway_usage_data, on="정류소명", how="left")
subway_final.to_csv(subway_optimized_path, index=False, encoding="cp949")
# 버스 데이터 정리 (버스 정류소 원본 데이터)
bus_raw_data = pd.read_csv(bus_raw_path, encoding="cp949")
bus_raw_data = bus_raw_data.drop(columns=["정류소아이디"], errors='ignore')
bus_raw_data["노선/호선"] = "버스"
bus_raw_data.to_csv(bus_optimized_path, index=False, encoding="cp949")
# 버스 승객 데이터 정리
bus_passenger_data = pd.read_csv(bus_passenger_raw_path, encoding="cp949")
bus_passenger_data.to_csv(bus_passenger_optimized_path, index=False, encoding="cp949")
# 카카오 API 설정
KAKAO_API_KEY = "개인 service key"
url_keyword = "https://dapi.kakao.com/v2/local/search/keyword.json"
headers = {"Authorization": f"KakaoAK {KAKAO_API_KEY}"}
# 버스 정류소 목록 추출
bus_station_names = bus_passenger_data["정류소명"].unique()
# API 요청을 통한 버스 정류장 검색
bus_results = []
for station in bus_station_names:
params = {"query": station, "size": 1} # 각 정류소명으로 검색
response = requests.get(url_keyword, headers=headers, params=params)
if response.status_code == 200:
result = response.json().get("documents", [])
if result:
data = result[0]
bus_results.append({
"정류소명": station,
"유형": "버스",
"주소": data.get("address_name", ""),
"위도": data.get("y", ""),
"경도": data.get("x", "")
})
else:
print(f"API 요청 실패: {station} (Status Code: {response.status_code})")
# 버스 정류장 API 데이터프레임 생성
bus_api_data = pd.DataFrame(bus_results)
# 지하철 데이터 API 요청 (카테고리 기반 'SW8' = 지하철)
CENTER_LAT = 37.38265 # 송도 위도
CENTER_LNG = 126.64894 # 송도 경도
subway_params = {
"category_group_code": "SW8", # 지하철역 코드
"x": CENTER_LNG,
"y": CENTER_LAT,
"radius": 5000,
"size": 15
}
subway_response = requests.get(url_keyword, headers=headers, params=subway_params)
subway_stations = subway_response.json().get("documents", []) if subway_response.status_code == 200 else []
subway_api_data = pd.DataFrame([{
"유형": "지하철",
"정류소명": s.get("place_name", ""),
"주소": s.get("address_name", ""),
"위도": s.get("y", ""),
"경도": s.get("x", "")
} for s in subway_stations])
# 버스 정류소 데이터 병합
bus_final = bus_raw_data.merge(bus_passenger_data, on="정류소명", how="left")
# API에서 가져온 좌표 및 주소 추가
bus_final = bus_final.merge(bus_api_data, on="정류소명", how="left")
# 최종 데이터 병합
songdo_transport_data = pd.concat([bus_api_data, subway_api_data], ignore_index=True)
# 전체 데이터 병합 후 저장
final_output_path = "final_transport_data.csv"
merged_transport = pd.concat([subway_final, bus_final, songdo_transport_data], ignore_index=True).drop_duplicates()
merged_transport.to_csv(final_output_path, index=False, encoding="utf-8")
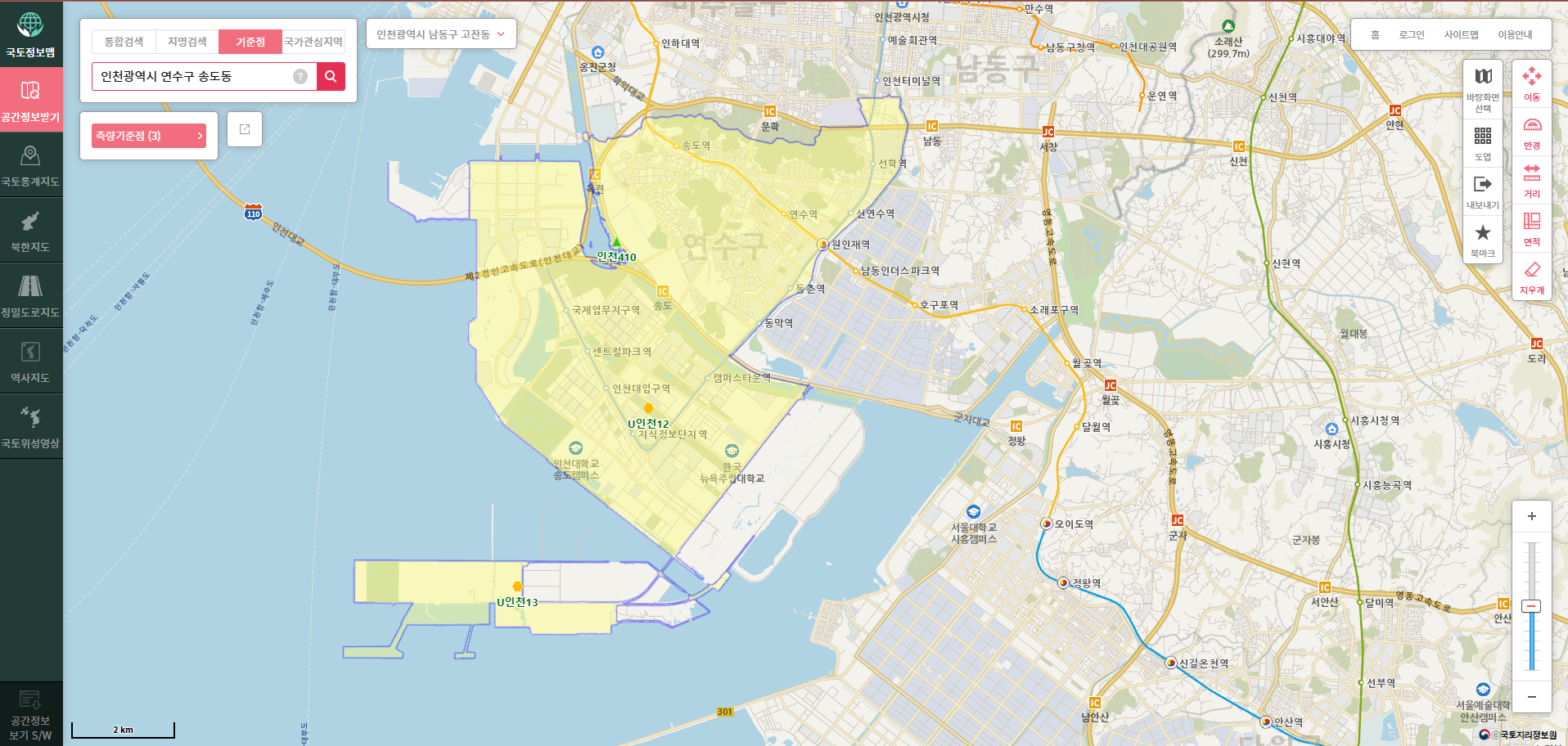
print("최종 통합 교통 데이터 저장 완료")송도동의 중심 위경도는 국토정보플랫폼의 측량기준점을 소수점 좌표로 변경한 값입니다.
위치를 좀 더 특정하자면, 미추홀 공원 내 장소입니다.

2) 데이터 정제 과정
'정류소명'과 '정류소번호'를 기준으로 중복된 행을 제거하는 것으로 시작합니다. 이어서 기준일자 컬럼을 '%Y%m%d' 형식의 datetime 타입으로 변환하고, 정류소번호와 정류소아이디는 결측값을 0으로 채운 후 정수형으로 변환합니다.
그 후, 위도와 경도 정보를 정리합니다. 이 때 여러 소스(예: 위도_x, 위도_y, 역위도) 중 가장 앞에 있는 값을 선택하여 소수점 5자리로 반올림한 후 위도와 경도 컬럼에 저장합니다. 또한, 컬럼 이름의 앞뒤 공백이나 특수문자를 제거하여 정리합니다.
불필요한 컬럼들을 정의한 후 삭제하고, 승하차 관련 컬럼 중 누락된 값은 다른 관련 컬럼(예: 승차인원, 하차인원)의 값으로 보완합니다. 행정동명과 지번주소에 '송도'라는 단어가 포함된 행만을 필터링하여 최종데이터를 저장합니다.
✔️ 중복 데이터 및 불필요한 컬럼 제거
✔️ 칼럼명 정리
✔️ 위도·경도 데이터 정리
✔️ 결측값 처리 및 데이터 보완 (총·하차건수 결측값을 승·하차인원으로 보완)
✔️ 송도 지역 데이터 필터링
데이터 정제 코드
import pandas as pd
# 원본 데이터 로드
file_path = "final_transport_data_complete.csv"
df = pd.read_csv(file_path)
# 중복 데이터 제거 (정류소명, 정류소번호 기준)
df = df.drop_duplicates(subset=['정류소명', '정류소번호'])
# 데이터 타입 변환
df['기준일자'] = pd.to_datetime(df['기준일자'], format='%Y%m%d', errors='coerce')
df['정류소번호'] = df['정류소번호'].fillna(0).astype(int)
df['정류소아이디'] = df['정류소아이디'].fillna(0).astype(int)
# 위도, 경도 정리 (소수점 5자리까지 반올림, 역위도/역경도 포함)
df['위도'] = df[['위도_x', '위도_y', '역위도']].bfill(axis=1).iloc[:, 0].round(5)
df['경도'] = df[['경도_x', '경도_y', '역경도']].bfill(axis=1).iloc[:, 0].round(5)
# 컬럼명 정리 (공백 및 특수문자 제거)
df.columns = df.columns.str.strip()
# 불필요한 컬럼 삭제
drop_cols = [
'기준일자', '정류소번호', '위도_x', '경도_x', '엑스좌표', '와이좌표', '노선/호선',
'위도_y', '경도_y', '노선번호', '역위도_x', '역경도_x', '운영기관명_x',
'역사도로명주소', '역사전화번호', '데이터기준일자', '철도운영기관명', '일자',
'위도', '경도', '역위도_y', '역경도_y', '운영기관명_y', '승차건수(카드)', '하차건수(카드)'
]
df = df.drop(columns=drop_cols, errors='ignore')
# NaN 값 처리 (총승차건수 및 총하차건수 보완)
df['총승차건수'] = df['총승차건수'].fillna(df['승차인원'])
df['총하차건수'] = df['총하차건수'].fillna(df['하차인원'])
# '행정동명' 및 '지번주소' 에서 '송도' 포함된 데이터 필터링
df_songdo = df[df['행정동명'].astype(str).str.contains('송도', na=False)]
df_songdo = df[df['지번주소'].astype(str).str.contains('송도', na=False)]
# 불필요한 컬럼 삭제 (송도 데이터 기준)
drop_cols_songdo = [
'승차건수(현금)', '환승역구분', '환승노선번호', '환승노선명', '역위도', '역경도',
'운영기관명', '선명', '지번주소', '도로명주소', '이용인원', '승차인원', '하차인원'
]
df_songdo = df_songdo.drop(columns=drop_cols_songdo, errors='ignore')
# 최종 데이터 저장
final_file_path = "final_processed_transport_data.csv"
df.to_csv(final_file_path, index=False, encoding='utf-8')
print(f"Final processed file saved at: {final_file_path}")3) 데이터 사용 컬럼
| 컬럼명 | 설명 |
|---|---|
정류소명 |
정류장 이름 |
권역 |
해당 정류장이 속한 권역 정보 |
행정동명 |
행정 구역 기준 송도 내 위치 |
정류소아이디 |
정류장의 고유 식별번호 |
총승차건수 |
해당 정류장에서의 총 승차 인원 |
총하차건수 |
해당 정류장에서의 총 하차 인원 |
일평균승하차건수 |
해당 정류장의 일평균 승·하차 인원 |
6. 생활 편의시설 데이터
1) 데이터 수집 및 정제 과정
인천 송도 지역의 상권 데이터를 수집하고 정제하여 최종 데이터셋을 구축하였습니다. 카카오 API 와 TMAP API를 활용해 키워드 및 카테고리 기반으로 카페, 편의점, 음식점 등 주요 상권 정보를 수집한 후, 이를 하나의 데이터로 병합했습니다.
데이터 정제 과정에서는 컬럼 구조를 통합하고 도로명 주소로 일관성을 유지했으며, 불필요한 컬럼(관리기관, 운영시간, 시설규모 등)을 제거하여 최적화했습니다. 중복 데이터는 위도와 경도를 기준으로 제거하고, 누락된 좌표나 연락처는 주소와 카카오 API를 활용해 보완했습니다. 마지막으로 송도 지역 데이터만을 필터링하여 분석에 용이한 형태로 최종 CSV 파일로 저장하였습니다.
✔️ 출처: 카카오 API, TMAP API
데이터 수집 및 정제 코드
import os
import time
import requests
import pandas as pd
# 환경변수에서 API 키 불러오기 (기본값은 예시)
KAKAO_API_KEY = os.environ.get("개인 KAKAO API KEY", "b4863b6c2ac0ffcff21852d82d421fa2")
TMAP_APP_KEY = os.environ.get("개인 TMAP APP KEY", "YOUR_TMAP_APP_KEY")
# requests 세션 생성
session = requests.Session()
# 카카오 API - 키워드 기반 장소 검색 (송도)
songdo_x, songdo_y = "126.64894", "37.38265"
keywords = ["카페", "편의점", "음식점", "지하철역", "버스정류장", "병원", "대형마트", "문화시설"]
all_data = []
for keyword in keywords:
for page in range(1, 4): # 최대 3페이지까지 수집
url = "https://dapi.kakao.com/v2/local/search/keyword.json"
headers = {"Authorization": f"KakaoAK {KAKAO_API_KEY}"}
params = {
"query": keyword,
"x": songdo_x,
"y": songdo_y,
"radius": 2000,
"page": page,
"size": 15
}
try:
response = session.get(url, headers=headers, params=params, timeout=10)
response.raise_for_status()
result = response.json()
except Exception as e:
break
if "documents" not in result:
break
if not result["documents"]:
break
df_temp = pd.DataFrame([{
"장소명": place.get("place_name"),
"카테고리": place.get("category_name"),
"주소": place.get("address_name"),
"도로명주소": place.get("road_address_name"),
"위도": place.get("y"),
"경도": place.get("x"),
"전화번호": place.get("phone"),
"장소 URL": place.get("place_url")
} for place in result["documents"]])
all_data.append(df_temp)
time.sleep(0.5) # API 호출 간 간격
if all_data:
final_df = pd.concat(all_data, ignore_index=True)
final_df.to_csv("songdo_places_kakao.csv", index=False, encoding="utf-8-sig")
# TMAP API - 상권(POI) 데이터 수집 (송도)
CENTER_LAT, CENTER_LON = 37.38265, 126.64894
CATEGORIES = "음식점;카페;병원;편의점"
url = "https://apis.openapi.sk.com/tmap/pois/search/around"
headers_tmap = {"Accept": "application/json", "appKey": TMAP_APP_KEY}
params_tmap = {
"version": 1,
"categories": CATEGORIES,
"centerLat": CENTER_LAT,
"centerLon": CENTER_LON,
"radius": 3000,
"count": 50
}
try:
response = session.get(url, headers=headers_tmap, params=params_tmap, timeout=10)
response.raise_for_status()
tmap_data = response.json()
except Exception as e:
tmap_data = None
poi_data = []
if tmap_data and "searchPoiInfo" in tmap_data and "pois" in tmap_data["searchPoiInfo"]:
pois = tmap_data["searchPoiInfo"]["pois"].get("poi", [])
for poi in pois:
poi_data.append({
"장소명": poi.get("name"),
"주소": poi.get("roadName") if poi.get("roadName") else (poi.get("upperAddrName", "") + " " + poi.get("middleAddrName", "")),
"위도": poi.get("frontLat"),
"경도": poi.get("frontLon"),
"카테고리": "상권"
})
df_tmap = pd.DataFrame(poi_data)
df_tmap.to_csv("songdo_poi_data.csv", index=False, encoding="utf-8-sig")
# 카카오 API - 카테고리 검색 (소형 상권 데이터)
center_lat, center_lng = 37.38265, 126.64894
CATEGORY_GROUPS = {
"카페": "CE7",
"음식점": "FD6",
"편의점": "CS2"
}
all_small_data = []
for category, code in CATEGORY_GROUPS.items():
page = 1
while True:
url = "https://dapi.kakao.com/v2/local/search/category.json"
headers_cat = {"Authorization": f"KakaoAK {KAKAO_API_KEY}"}
params_cat = {
"category_group_code": code,
"x": center_lng,
"y": center_lat,
"radius": 1000,
"sort": "distance",
"page": page
}
try:
response = session.get(url, headers=headers_cat, params=params_cat, timeout=10)
response.raise_for_status()
data = response.json()
except Exception as e:
break
if "documents" not in data:
break
if not data["documents"]:
break
for place in data["documents"]:
all_small_data.append({
"시설명": place.get("place_name"),
"유형": category,
"주소": place.get("road_address_name") or place.get("address_name"),
"위도": place.get("y"),
"경도": place.get("x"),
"연락처": place.get("phone")
})
if len(data["documents"]) < 15:
break # 마지막 페이지 도달
page += 1
time.sleep(0.3)
df_small = pd.DataFrame(all_small_data)
df_small.to_csv("songdo_small_store.csv", index=False, encoding="utf-8-sig")
# 카카오 API - 키워드 및 카테고리 통합 데이터 수집 (송도)
SONGDO_X, SONGDO_Y = "126.64894", "37.38265"
keywords_kakao = ["편의점", "카페", "음식점", "병원", "대형마트", "문화시설"]
places_data = []
# 키워드 검색
for keyword in keywords_kakao:
url = "https://dapi.kakao.com/v2/local/search/keyword.json"
headers_kw = {"Authorization": f"KakaoAK {KAKAO_API_KEY}"}
params_kw = {
"query": keyword,
"x": SONGDO_X,
"y": SONGDO_Y,
"radius": 3000,
"size": 15
}
try:
response = session.get(url, headers=headers_kw, params=params_kw, timeout=10)
response.raise_for_status()
result = response.json()
except Exception as e:
continue
if result and "documents" in result:
for place in result["documents"]:
places_data.append({
"장소명": place.get("place_name"),
"카테고리": place.get("category_name"),
"주소": place.get("address_name"),
"위도": place.get("y"),
"경도": place.get("x")
})
time.sleep(1)
# 카테고리 코드 검색
category_codes = ["CS2", "FD6", "CE7", "MT1", "CT1", "HP8"]
for code in category_codes:
page = 1
while True:
url = "https://dapi.kakao.com/v2/local/search/category.json"
headers_cat2 = {"Authorization": f"KakaoAK {KAKAO_API_KEY}"}
params_cat2 = {
"category_group_code": code,
"x": SONGDO_X,
"y": SONGDO_Y,
"radius": 3000,
"size": 15,
"page": page
}
try:
response = session.get(url, headers=headers_cat2, params=params_cat2, timeout=10)
response.raise_for_status()
data = response.json()
except Exception as e:
break
if "documents" not in data:
break
if not data["documents"]:
break
for place in data["documents"]:
places_data.append({
"장소명": place.get("place_name"),
"카테고리": place.get("category_name"),
"주소": place.get("address_name"),
"위도": place.get("y"),
"경도": place.get("x")
})
if len(data["documents"]) < 15:
break
page += 1
time.sleep(1)
df_kakao = pd.DataFrame(places_data)
df_kakao.to_csv("songdo_kakao_poi_data.csv", index=False, encoding="utf-8-sig")
# 여러 CSV 파일 병합 및 최종 파일 생성
poi_files = [
"songdo_places_kakao.csv",
"songdo_kakao_poi_data.csv",
"songdo_poi_data.csv",
"songdo_small_store.csv"
]
poi_dfs = []
for file in poi_files:
try:
df_tmp = pd.read_csv(file)
if not df_tmp.empty:
poi_dfs.append(df_tmp)
except Exception as e:
pass
if poi_dfs:
merged_df = pd.concat(poi_dfs, ignore_index=True)
merged_df = merged_df.drop_duplicates(subset=['위도', '경도'], keep='first')
else:
merged_df = pd.DataFrame()
# 추가 파일 병합 (fin_convenience_df.csv 미리 만들어두기)
new_poi_file = "fin_convenience_df.csv"
try:
df_new = pd.read_csv(new_poi_file)
if not df_new.empty:
merged_df = pd.concat([merged_df, df_new], ignore_index=True)
merged_df = merged_df.drop_duplicates(subset=['위도', '경도'], keep='first')
except Exception as e:
pass
# 불필요한 컬럼 제거
drop_columns = ['카테고리', '도로명주소', '전화번호', '장소 URL', '유형', '연락처']
cols_to_drop = [col for col in drop_columns if col in merged_df.columns]
merged_df = merged_df.drop(columns=cols_to_drop)
merged_df.to_csv("fin_convenience.csv", index=False, encoding='utf-8-sig')

2) 데이터 사용 컬럼
| 컬럼명 | 설명 |
|---|---|
장소명 |
시설의 이름 (카카오 API의 "장소명". 소형 상권 데이터의 "시설명" 의미) |
주소 |
도로명 주소를 기준의 주소 정보 |
위도 |
시설의 지리적 위치를 나타내는 위도 값 |
경도 |
시설의 지리적 위치를 나타내는 경도 값 |
7. 금융 및 금리 데이터
1) 데이터 수집 과정
한국은행 홈페이지에서 기준금리 데이터를 웹 크롤링하여 CSV 파일로 저장합니다.
HTTP GET 요청과 User-Agent 설정을 통해 웹 페이지를 받아온 후, BeautifulSoup으로 HTML을 파싱하여 기준금리 정보가 포함된 테이블의 각 행에서 연도, 변경일자,기준금리 값을 추출합니다. 추출된 데이터를 DataFrame으로 정리한 후, 각 년도별 최신 데이터를 선별합니다. 연도와 변경일자 정보를 결합하여 날짜 형식으로 변환하고 불필요한 연도 컬럼을 삭제합니다.
✔️ 출처: 한국은행 기준금리 추이, 한국은행 경제통계시스템(ECOS)
데이터 수집 코드
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 대상 URL 및 요청 헤더 설정
url = 'https://www.bok.or.kr/portal/singl/baseRate/list.do?dataSeCd=01&menuNo=200643'
headers = {
'User-Agent': (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/109.0.0.0 Safari/537.36"
)
}
# URL에 GET 요청하여 HTML 데이터 수집 및 파싱
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 기준금리 정보가 포함된 테이블 찾기
table = soup.find("table", class_="fixed")
rows = soup.find('tbody').find_all('tr')
# 테이블의 각 행에서 연도, 변경일자, 기준금리 추출
data_list = []
for row in rows:
cols = row.find_all('td')
year = cols[0].text.strip() # 연도
date = cols[1].text.strip() # 변경일자
rate = float(cols[2].text.strip()) # 기준금리 (실수형으로 변환)
data_list.append([year, date, rate])
# 추출한 데이터를 DataFrame으로 변환 후, 컬럼명 지정
rate_df = pd.DataFrame(data_list, columns=['년도', '변경일자', '기준금리'])
# 각 년도별 첫 번째(최신) 데이터 선택
latest_rates = rate_df.groupby("년도").first().reset_index()
# DataFrame을 CSV 파일로 저장 (초기 저장)
latest_rates.to_csv("rate.csv", index=False, encoding='utf-8')
# 연도와 변경일자를 결합하여 날짜 형태로 변환
df_dates = latest_rates.copy()
df_dates['변경일자'] = (
df_dates['년도'].astype(str) + '-' +
df_dates['변경일자'].replace({'월 ':'-', '일':''}, regex=True).str.strip()
)
# 연도 정보는 별도로 필요 없으므로 삭제
df_dates.drop(columns='년도', inplace=True)
# 최종 데이터를 CSV 파일로 다시 저장
df_dates.to_csv("interest_rates.csv", index=False, encoding='utf-8')
print("기준금리 데이터가 CSV 파일로 저장되었습니다.")2) 데이터 정제 과정
정책금리 데이터의 변경일자 정보를 datetime 형식으로 변환하여 해당 날짜에서 연도와 월을 추출한 후, 이를 기준으로 월별 정보를 생성합니다. 정책금리의 적용 시점이 거래 발생 시점보다 앞서 적용되도록 추출된 연월 정보에서 1개월을 차감한 값을 별도로 생성합니다. 이 값을 기준으로 그룹화하여 각 기간의 마지막 금리 값을 선택합니다. 선택된 값은 이후 Policy Rate라는 명칭으로 재정의합니다.
국고채 금리 데이터에서는 10년 만기 국고채 금리를 선택합니다. 데이터 중 필요한 부분만을 추출하여 데이터의 행과 열을 전치한 후, 단일 컬럼으로 정리합니다. 전치된 데이터의 인덱스를 날짜 형식으로 변환하여 연도와 월 정보를 도출하고, 이를 year_month 컬럼으로 설정합니다. 이렇게 준비된 두 데이터셋은 각각 월별 기준 정보를 포함하게 됩니다.
마지막으로, 정책금리 데이터와 국고채 금리 데이터를 year_month 컬럼을 기준으로 병합하여 하나의 통합 데이터셋으로 결합합니다. 이 과정에서 정책금리 값에 결측치가 발생할 경우, 바로 이전 또는 이후의 값을 사용하여 보완함으로써 데이터의 일관성을 유지합니다.
데이터 정제 코드
import pandas as pd
# 정책금리 데이터 로드 및 전처리
policy_rate_raw = pd.read_csv("interest_rates.csv")
policy_rate_raw['변경일자'] = pd.to_datetime(policy_rate_raw['변경일자'])
policy_rate_raw['year_month'] = policy_rate_raw['변경일자'].dt.to_period('M')
# 정책금리가 한 달 이전 기준으로 적용되도록 처리
policy_rate_raw['prev_year_month'] = policy_rate_raw['year_month'] - 1 # 이전 달 생성
policy_rate_monthly = policy_rate_raw.groupby('prev_year_month')['기준금리'].last().reset_index()
policy_rate_monthly.rename(columns={'prev_year_month': 'year_month', '기준금리': 'Policy Rate'}, inplace=True)
# 국고채(시장금리) 데이터 로드 및 전처리
bond_yield_raw = pd.read_csv("bond_yield.csv")
# '항목명1'이 '국고채(10년)'인 데이터만 선택 후, 6번째 열부터 추출하여 전처리
bond_yield_filtered = bond_yield_raw[bond_yield_raw['항목명1'] == '국고채(10년)'].iloc[:, 5:].T
bond_yield_filtered.columns = ['Market Interest Rate']
bond_yield_filtered.index = pd.to_datetime(bond_yield_filtered.index, format='%Y/%m')
bond_yield_monthly = bond_yield_filtered.copy()
bond_yield_monthly['year_month'] = bond_yield_monthly.index.to_period('M')
# 정책금리와 국고채 금리 데이터를 'year_month'를 기준으로 병합
merged_df = pd.merge(
policy_rate_monthly,
bond_yield_monthly.reset_index()[['year_month', 'Market Interest Rate']],
on='year_month',
how='left'
)
# 결측값 보완: Policy Rate의 NaN 값은 앞뒤 값으로 채움
merged_df['Policy Rate'] = merged_df['Policy Rate'].fillna(method='ffill').fillna(method='bfill')
# 최종 데이터 저장
output_path = "fin_interest_bond.csv"
merged_df.to_csv(output_path, index=False)
print(f"Merged data saved to {output_path}")3) 데이터 사용 컬럼
| 컬럼명 | 설명 |
|---|---|
year_month |
연도와 월 정보(기준금리 및 시장금리 데이터의 기간) |
Policy Rate |
변경일자 이전 기준으로 적용된 중앙은행의 정책금리 |
Market Interest Rate |
국고채(10년) 금리(시장금리) |
🧭 마무리
2015년부터 2024년까지 송도동 아파트 매매 실거래가 데이터를 비롯해 교통, 인프라, 생활 편의시설, 금융 금리 데이터까지 수집하고 전처리하는 작업을 완료했습니다.
실제 데이터를 수집하고 정리하는 과정에서 데이터 분석가에게는 단순한 분석 기술뿐만 아니라, 신뢰할 수 있는 데이터를 확보하고 정제하는 역량이 중요하다는 점을 깨달았습니다. 우리나라에는 통계청과 다양한 데이터 포털이 있지만, 각기 다른 출처에서 데이터를 모으고 목적에 맞게 정제하는 과정이 결코 쉽지 않았습니다. 하지만 이번 경험을 통해 데이터 수집과 전처리의 핵심 원리를 몸소 체감할 수 있었습니다.
🚢 이제 항해의 닻을 올릴 시간입니다.
이제 데이터를 정리하고 항해 준비를 마쳤습니다. 다음 여정에서는 탐색적 데이터 분석(EDA)을 통해 바다의 지형을 살피고, 아파트 가격 예측 모델을 구축하며 새로운 항로를 개척하는 과정을 공유하겠습니다.
🌊 앞으로의 항해도 함께해 주세요!
Reference
1. 구본일, 김재익, 소지역 단위의 주택시장 불안정 진원지 파악에 관한 연구
2. 김진성, 실거래가로 살펴본 전월세시장 동향
3. 박진배,이수욱,이태리,전성제, 권건우 외, 부동산세제의 시장 영향력과 향후 정책방향 연구
4. 박천규, 김태환,김대진, 박미선, 전월세시장 행태 및 인식 변화와 시사점
5. 배상영, 이혜진, 전세의 두 얼굴-24년은 여전히 공급보다는 정책과 금리
🚢 데이터의 바다는 넓고, 우리의 항해는 계속됩니다.
다음 여정에서 또 만나요! 😎🌊
'데이터 프로젝트 > 송도 국제도시 아파트 실거래가 분석' 카테고리의 다른 글
| [6] 송도국제도시 공구별 특성 분석: 1공구, 6공구, 8공구를 중심으로 (6) | 2025.04.15 |
|---|---|
| [5] 부동산 가격 예측을 위한 회귀 기반 모델링과 변수 해석 (0) | 2025.04.07 |
| [4] 탐색적 데이터 분석(EDA) (2) | 2025.04.01 |
| [3] 데이터 전처리 및 기초 통계 분석 (2) | 2025.03.26 |
| [1] 송도 국제도시 아파트 실거래가 분석 프로젝트 개요 (2) | 2025.03.08 |